Event-Driven Data Management for Microservices
Event-Driven Data Management for Microservices에 대한 요약이다.
Microservices and the Problem of Distributed Data Management
모놀리틱(monolithic) 어플리케이션은 전형적으로 단일 관계형 데이터베이스를 사용한다.
RDB 의 가장 큰 장점 중 하나는 ACID 트랜젝션 을 지원한다는 것이다.
- 원자성(Atomicity) : Changes are made atomically
- 일관성(Consistency) : The state of the database is always consistent
- 격리성(Isolation) : Even though transactions are executed concurrently it appears they are executed serially
- 지속성(Durable) : Once a transaction has committed it is not undone
또 다른 장점 중 하나는 SQL 을 지원하는 것 이다.
여러 테이블을 쉽게 JOIN 할 수 있고, 쿼리를 최적화된 방법으로 실행해 준다.
따라서 내부적으로 어떻게 데이터베이스에 접속하고 처리하는지에 대해 자세히 몰라도 된다.
하지만, 마이크로서비스 아키텍쳐는 데이타에 접근하는 것이 더욱 복잡해 진다.
각 마이크로서비스 마다 자신의 데이터를 소유하고 다른 서비스에서는 API를 통해서 접근할 수 있다.
(참고: Pattern: Database per service)
이렇게 데이타를 캡슐화하면 서비스들 간의 결합도를 줄이게 되고(loosely coupled), 다른 서비스들과 독립적으로 수정가능하다.
여러서비스가 같은 데이터를 접근한다면, 스키마(schema)를 수정하고
관련된 모든 서비스들을 수정해야 되기 때문에 많은 시간이 소요된다.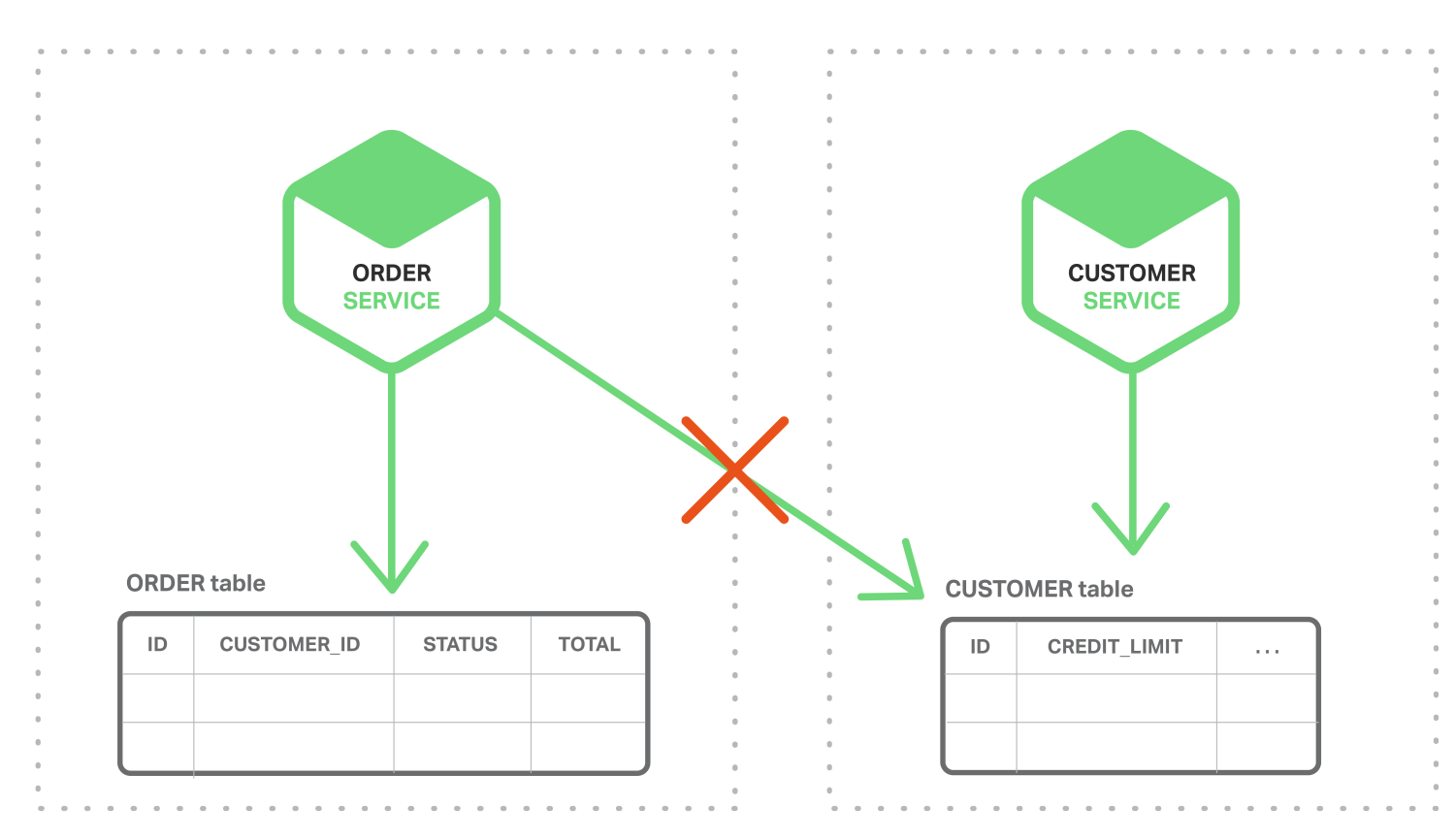
각 마이크로서비스들은 상황에 따라 다른 데이터베이스를 사용하곤한다. 요즘 어플리케이션이 저장하고 처리하는 데이터의 종류가 다양해졌기 때문에,
RDB가 항상 최선의 선택인 것은 아니다.
예를 들면, NoSQL database 의 경우 유연한 데이터모델을 가지고 성능이나 확장성(scalability)면에서 더 나을 것이다.
예: 텍스트 서치의 경우 Elasticsearch, social graph data의 경우 Neo4j같은 그래프 데이터베이스
마이크로서비스 기반의 어플리케이션은 SQL, NoSQL 데이터베이스를 섞어서 사용하는 경우도 있다.
(참고: polyglot persistence)
polyglot persistence 아키텍쳐는 loosely coupled 한 서비스를 만들고 성능 및 확장성 등 많은 장점들을 갖는 반면
분산된 데이터 관리에 대한 어려움이 있다.
여러 서비스간 데이터 일관성(Consistency) 은 어떻게 구현 할 것인가?
고객 서비스와 주문 서비스가 있는 경우 monolithic 에서는 ACID 트랜젝션으로 묶어 처리할 수 있지만,
MSA 에서는 테이블을 직접 참조하지 못하고 API를 통해서만 접근이 가능할 것이다.
이를 위해 2PC라고 알려진 분산 트랜젝션(Distributed Transaction)을 사용 할 수 있을 것이다.
하지만 일반적으로 최근 어플리케이션에서는 2PC가 사용되지 않는다.
CAP 이론은 가용성(Availability)과 ACID 스타일의 일관성 사이에서 선택을 요구한다.
NoSQL DB의 대부분은 2PC를 지원하지 않고 가용성을 더 중요하게 생각한다.여러 서비스로 부터 데이터 조회 하는 쿼리는 어떻게 구현 할 것인가?
고객 정보와 고객의 최근 구매이력을 조회하려고 할 때, 고객 서비스와 주문 서비스의
API를 사용하여 application-side join을 할 수 있을 것이다.
하지만 만약, 주문 이력이 NoSQL에 저장되어 있고, PK로만 조회가 가능하다면 필요한 정보를 어떻게 받아야 할까?
Event-Driven Architecture
이런 문제를 해결하기 위해 많은 어플리케이션에서 Event-Driven Architecture가 사용한다.
서비스들은 비지니스 엔티티가 변경되는 등의 주요 작업이 발생한 경우, 이벤트를 발행(publish)한다.
다른 서비스에서 이 이벤트에 관심이 있는 경우 구독(subscribe) 하여 다음 작업을 처리하면 된다.
이런 이벤트를 통해 여러 서비스간 비지니스 트랜젝션을 구현 할 수 있다.
서비스에서 이벤트를 받아 다음 스텝의 작업을 처리하고 다시 이벤트를 발행하면서 처리해 나갈 수 있다.
- The Order Service creates an Order with status NEW and publishes an Order Created event.
- The Customer Service consumes the Order Created event, reserves credit for the order, and publishes a Credit Reserved event.
- The Order Service consumes the Credit Reserved event, and changes the status of the order to OPEN.
각 서비스들은 원자적(atomically)으로 데이터베이스를 업데이트하고, 이벤트를 발행한다.
Message Broker가 각 이벤트들이 최소 한번은 전달됨을 보장해 줌으로써,
이를 통해 여러 서비스간 비지니스 트랜젝션을 구현한다.
이는 ACID 트랜젝션은 아니지만 Eventual Consistency 를 제공 할 수 있다.
또한 이벤트를 이용하여 pre-join된 view를 제공 할 수 있다.
예를 들어, 고객 서비스와 주문 서비스가 발행하는 이벤트를 구독하여 Customer Order View Query 서비스를 만들 수도 있다.
Event-Driven Architecture는 몇가지 장단점이 있다.
여러 서비스간 사용되는 트랜젝션을 구현 할 수 있고, Eventual Consistency를 제공해 준다.
그리고 pre-join된 View를 생성하여 제공 할 수도 있다.
반면, ACID 트랜젝션을 사용하는 것에 비해 구현하기 더 복잡하다.
오류가 발생한 경우 어플리케이션 레벨에서 취소하는 보상 트랜젝션을 구현해야 한다.
또한, View를 사용하는 경우 아직 반영되지 않은 데이터에 대해서 불일치하는 문제가 발행 할 수도 있고,
중복된 이벤트를 검출해 내고 이를 무시하는 기능도 구현해야된다.
Achieving Atomicity
Event-Driven Architecture에서 데이터베이스를 업데이트하고, 이벤트를 발행하는 작업이 반드시 원자적으로 이루어져야 하는 문제가 있다.
만약 데이터베이스를 업데이트하고 이벤트를 발행하기 전에 문제가 생겼다면 시스템은 불일치하게 된다.
Publishing Events Using Local Transactions
메세지 큐와 같은 기능을 하는 EVENT 테이블을 비지니스 엔티티 테이블과 같은 데이터베이스에 만든다.
비지니스 엔티티를 수정하고, 이벤트를 EVENT 테이블에 insert하는 기능을 한 로컬 트랜젝션으로 수행한다.
이런 방법은 2PC없이 이벤트가 발행되는 것을 보장해 주는 장점이 있는 반면,
개발자가 이벤트 발행하는 것을 잊어버리는 등의 잠재적인 위험이 있다.![]()
Mining a Database Transaction Log
데이터베이스의 Transaction/commit log를 수집하여 이벤트를 발행하는 방법이 있다.
관련 기술로는 LinkedIn Databus, AWS DynamoDB streams mechanism 등이 있다.
2PC 없이 이벤트 발행을 보장해주고 비지니스 로직과 이벤트 발행 기능을 분리할 수 있다는 장점이 있다.
반면, 데이터베이스마다 로그의 포멧이 다르고, 버전 사이에도 차이가 있을 수있다.
또한 low-level 로그를 통해 high-level 비지니스 이벤트를 생성해 내야하는 어려움이 있다.![]()
Using Event Sourcing
Event Sourcing 은 엔티티의 현재상태를 저장하는 대신, 상태를 변경하는 이벤트를 순서대로 저장하는 방법이다.
어플리케이션은 이벤트들을 replay 하면서 현재상태를 재구성한다.
이벤트들은 Event Store 라는 데이터베이스에 저장된다.
Event Store는 Message Broker와 같은 역할도 동시에 수행한다.
Event Sourcing 방법을 사용하면 여러 장점이 있다.
상태가 변경될 때마다 이벤트가 발생되는 것을 보장해야 하는 Event-Driven Architecture의 문제를 해결 함으로써
MSA의 데이터 일관성 문제를 해결 할 수 있다.
또한 이벤트를 저장하기 때문에 객체와 관계형 DB의 불일치 문제를 피할 수도 있다.
뿐만아니라 특정 시점의 엔티티의 상태를 조회할 수 있다.
Event Sourcing의 단점으로는
익숙하지 않은 프로그래밍 스타일이고 학습하는데 시간이 걸린다.
Event Store는 PK를 통해서만 엔티티를 조회 할 수 있기 때문에 CQRS를 반드시 적용해야 하고, eventually consistent data를 다뤄야 한다.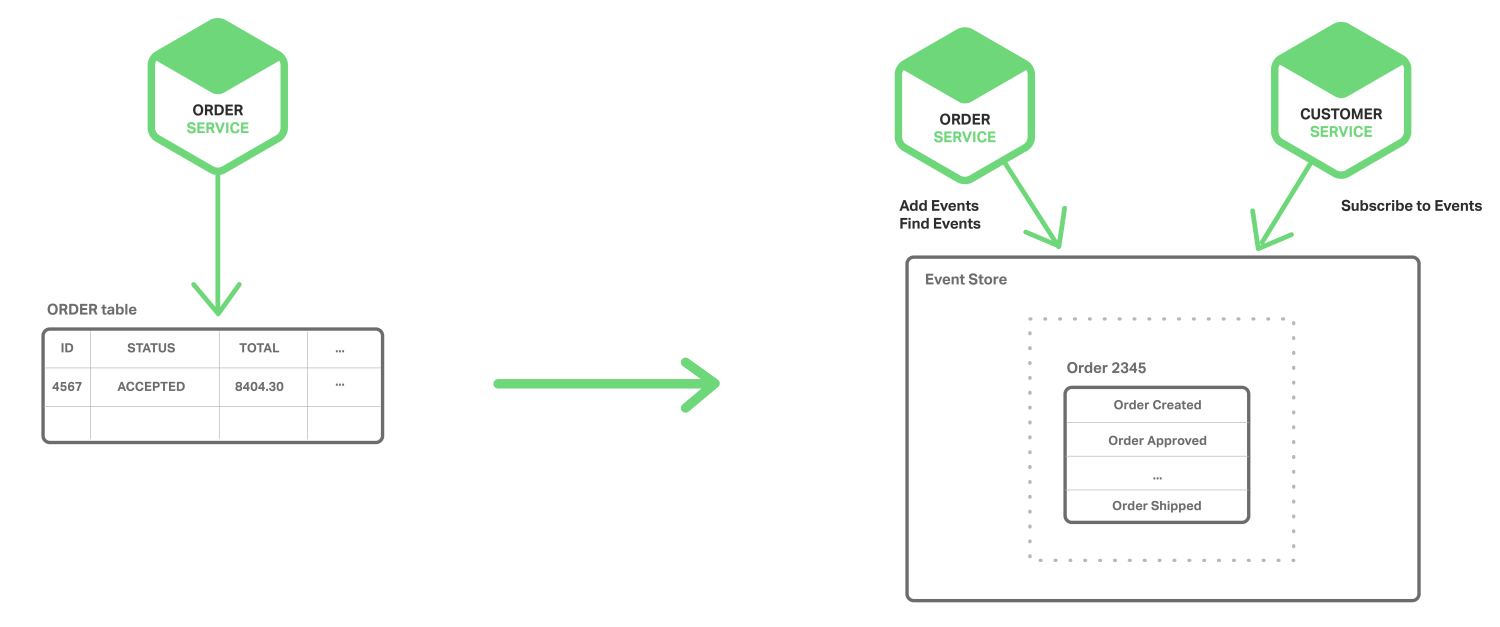
Summary
마이크로서비스 아키텍쳐에서 각 서비스틀은 자신만의 고유한 데이터베이스를 가진다.
이런 아키텍쳐는 여러 장점을 가지는 반면에 분산된 데이터를 관리해야 하는 어려움이 있다.
서비스간 일관성을 유지하기 위한 트랜젝션을 구현해야 되고, 여러서비스에서 데이터를 조회해야 하는 어려움이 있다.
이를 위해 많은 어플리케이션에서 Event-Driven Architecture 를 사용하고 있다.
하지만 엔티티의 상태를 업데이트하고 이벤트를 발행하는 것을 atomically 하게 구현해야 하는 어려움이 있다.
이를 해결하기 위해 데이터베이스를 메시지 큐로 사용하는 방법,
데이터베이스의 트랜젝션 로그를 수집하는 방법, Event Sourcing을 사용하는 방법 등이 있다.